A Likert-skála fogalma és 3 fajta módszer az elemzésére
A Likert-skála két szélsőséges érték közötti mérési skála, amely az attitűd mérésére szolgál. Gyakran használják kvantitatív kutatások során adott fogalommal, tevékenységgel kapcsolatos attitűdök mérésére, piackutatások vagy személyiség tesztek során.
Általában 1-5-ig, 1-7-ig vagy 1-10-ig terjed. A leggyakoribb az 1-5-ig terjedő egyetértési skála, ahol az 1-es érték az „egyáltalán nem ért egyet” és az 5 a „teljes mértékben egyetért”, vagy fordítva. A 3 pedig semleges, „igen is, meg nem is” vagy „nem tudom eldönteni”.
A Likert-skála jellemzői
A Likert-skálának lehet páros (pl. 1-4) vagy páratlan (pl. 1-5) számú pontja, fokozata. Ha azt szeretnénk elérni, hogy a válaszadó határolja el magát valamelyik irányba, akkor ajánlott páros számú pontot megadni, hiszen így döntésre késztetjük a válaszadót. Páratlan válaszlehetőség esetén a középső érték semleges, ami egyben a „kényelmes” válasz is, hiszen előfordulhat olyan kérdés is, amelyre a válaszadó nem tud rögtön határozottan válaszolni és ilyenkor ha van köztes lehetőség, akkor azt választja az átgondolás helyett.

A kérdések számát tekintve két féle Likert-skálát különböztetünk meg:
- Egy kérdéses skála
- Több kérdéses (kérdéscsoportos) skála
A Likert-skála kérdésére/kérdéseire adott válaszokkal elvégezhető műveletek:
- Gyakorisági eloszlás
- Módusz
- Medián (amennyiben intervallum mérési szintű változónak tekintjük)
Egyes kutatók a likert-skálát ordinális változóként, míg mások intervallum mérési szintű változóként tekintik. Hasznos információval szolgál hatásvizsgálatoknál vagy időrendi változások vizsgálatánál. Példa: Egy gyógytorna hatásának a vizsgálata derékfájás esetén Likert-skála segítségével. Megkérdezzük, hogy a terápia előtt és után milyen gyakran fájt a válaszadó dereka. A választ egy 1-5-ig terjedő skálán kell megjelölni, ahol az 1-Soha és az 5-Mindig. Az átlag növekedése vagy csökkenése utal a gyógytorna eredményességére. Viszont először meg kell nézni, hogy a két változó között kimutatható-e szignifikáns összefüggés.
Kérdéscsoportok esetében az összegzett válaszértékek, összefüggések többletinformációval szolgálnak. Ez a fajta Likert-skála elterjedt a pszichológusok körében, több teszt alapját is képezi, példa erre a Beck-féle depresszió kérdőív vagy az Állapot szorongás kérdőív. Szintén közkedvelt a piackutatók körében, mivel ideális módszer a fogyasztói igények felmérésére. A kérdéscsoport esetében figyelni kell arra, hogy minden kérdésnél ugyanaz a skála legyen alkalmazva.
A Likert-skála előnyei
- Elkészítése gyors és könnyű, viszonylag egyszerű konstrukció.
- Egyaránt használható kérdezőbiztos révén kitöltött kérdőív, önkitöltős vagy akár telefonos és elektronikus úton történő lekérdezés esetén is.
- Viszonylag gyors a feldolgozás és értelmezés.
A Likert-skála hátrányai
A semleges válaszlehetőség dilemmája: Amennyiben úgy döntünk, hogy hagyunk egy köztes válaszlehetőséget, előfordulhat, hogy a válaszadó nem határolja el magát egyik irányba sem. Amennyiben nincs ez a lehetőség, előfordulhat, hogy a válaszadónak nem adunk lehetőséget arra, hogy kifejezhesse semlegesnek ítélt attitűdjét a vizsgálat tárgyával kapcsolatban.
Főként piackutatás, marketingkutatás terén alkalmazzák leggyakrabban a páratlan pontszámú skála használatát, amikor mindenképpen az a cél, hogy az egyén határolja el magát az egyik irányba. Személyiség vizsgálat esetén a köztes válaszlehetőség kibúvónak is szolgálhat, mivel ebben az esetben gyakoribbak az olyan kérdések, amelyek komolyabb elgondolkodást igényelnek.
Egy kutató saját maga kell eldöntse, hogy melyik szempontot részesíti előnyben. Véleményem szerint az attitűdök mérésére alkalmas kérdések a teljes mértékben egyetértéstől a semlegesességen keresztül a teljes elutasításig terjedhetnek. Tehát én a semleges válaszlehetőség feltüntetését részesítem előnyben. A mindennapi életben is előfordul az, hogy valamivel szemben egyszerűen csak semlegesen viszonyulunk.
A megfelelés igénye: A válaszadó nem a saját attitűdjeinek megfelelő választ adja meg, hanem amit szerinte jónak/megfelelőnek gondol a társadalom.
Felületesség: Főleg a több kérdésből álló skálák esetében jelent kockázatot. Kérdéscsoport esetén előfordulhat, hogy a válaszadó átgondolás nélkül, csak az ugyanazon sorban lévő válaszlehetőséget adja meg, pl. mindennel egyetért, semmivel sem ért egyet.
Kitöltési hiba: Könnyen előfordulhat, főleg a táblázatok esetén, hogy a válasz elcsúszik, kimarad egy sor stb.
Mire kell még odafigyelni?
Mielőtt belevágnánk a skála elemeinek megszerkesztésébe, fontos részleteibe menően átgondolni a kutatás témáját. A skála hossza, páratlan vagy páros mivolta nem a véletlen műve kell legyen!
Amennyiben különböző okok miatt (pl. az alapsokaság mérete miatt) kisebb mintára számítunk, ajánlott kevesebb ponttal rendelkező Likert-skálát használni a pontosság és megbízhatóság érdekében (ha kevés az esetszám, akkor az összefüggések kisebb pontossággal és valószínűséggel állíthatóak, és ha a válaszok több válaszlehetőség között oszlanak el, annál bizonytalanabbak lesznek a változók közötti kapcsolatok), viszont több válaszlehetőséggel részletesebb válaszlehetőségeket adhatunk meg.
Likert-skála szerkesztése Google űrlapban
Egy kellően jól megszerkesztett kutatási terv elkészítése után a kérdőív könnyen megszerkeszthető a Google űrlap segítségével.
A Google Drive „Új” menüjére kattintva nyithatunk meg egy új „Google Űrlap”-ot.
A Google űrlap használata ingyenes, hozzáférést biztosítanak a nyers adatokhoz is, valamit letölthető egy automatikusan generált összegzés, táblázatokkal szemléltetve.
A megnyitott űrlapnak kell tartalmaznia egy címet, valamint egy rövid leírást, arról, hogy kik vagyunk, mit és miért szeretnénk felmérni.
Amint ezzel megvagyunk, jöhetnek a kérdések. A kérdés típusánál kiválasztjuk a lineáris skálát és megadjuk a kérdést, majd meghatározzuk a skála hosszát. Az első és utolsó érték címkéjét (pl. egyáltalán nem, teljes mértékben) nem kötelező megadni, viszont javasolt, hiszen másképpen a válaszadó csak sejtheti, hogy mit jelentenek a válaszopciók.
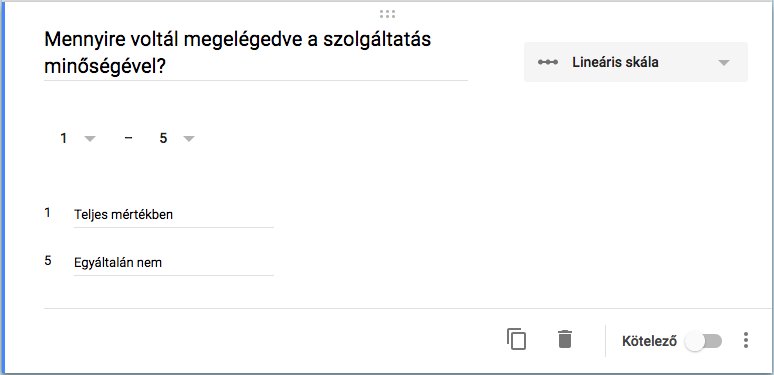
Több kérdéses Likert-skála készítése
A kérdés típusánál kiválasztjuk a feleletválasztós rácsot, majd megadjuk a kérdést. A sorokhoz beírjuk a változókat az oszlopnál pedig megadjuk a skála pontjainak értékét.
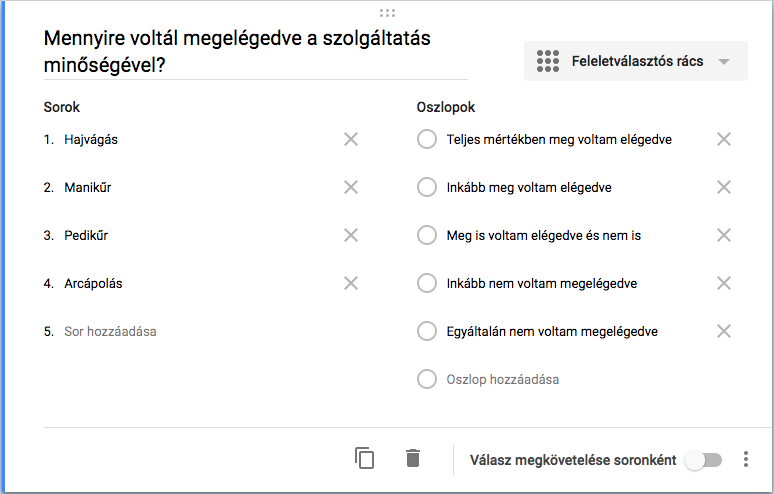
Szerkesztés után az alábbi formája lesz a kérdésnek:

A Likert-skála adatainak feldolgozása SPSS-ben
Gyakoriság megtekintése
A gyakoriság az Analyze-Descriptive Statistics almenüben található Frequencies parancsra kattintva kérhető le. A megjelenő ablak bal oldalán kiválasztjuk azt a változót, amelynek meg szeretnénk nézni a gyakoriságát és az Ok gombra kattintunk. A megjelenő output ablakban megnézhetjük, hogy a válaszok hogyan oszlanak el a megadott válaszlehetőségek között. Az eloszlás abszolút és relatív értéken is fel van tüntetve.
Medián, Módusz
Szintén az Analyze-Descriptive Statistics almenüben található Frequencies parancsra kattintva kérhetőek le. A megjelenő ablakban, a változó kiválasztása után a Statistics gombra kattintunk. Ekkor egy új ablak jelenik meg, ahol kijelöljük a kívánt mutatót és a Continue gombra, majd az Ok gombra kattintunk. A megjelenő outputban megtekinthetők a kért mutatók.
1. módszer: Likert skálák közötti kapcsolatok vizsgálata a Khi négyzet próbával
A Likert-skálák közötti kapcsolatok vizsgálatát a Khi négyzet próbával végezhetjük el. Amennyiben szignifikáns kapcsolatot fedezünk fel, akkor érdemes a kapcsolat erősségét is megvizsgálni. A kapcsolat erősségét a Gamma-mutató méri, amelynek értéke -1 és 1 között van. Amit még fontos tudni, az az hogy nem kötelező, hogy a skálák ugyanazok legyenek.
Az Spss-ben az Analyze-Descriptive Satatistics-Crosstabs menüpontnál kérhető le. A megjelenő ablakban a Statistics gombra kattintva kijelöljük a Gamma mutatót, majd Continue és Ok. A megjelenő kereszttábla nem minden esetben értelmezhető, viszont a megjelenő ablakban megnézhetjük a szignifikancia szintet (Approx. Sign.). Amennyiben az érték kisebb, mint 0,05, a két változó között van szignifikáns kapcsolat és megvizsgálhatjuk a Gamma értékét (Value). Amennyiben az érték negatív, a két változó között fordított a kapcsolat. Minél jobban közelít az érték az 1-hez vagy fordított kapcsolat esetén a -1-hez, annál erősebb a kapcsolat. Ebben az esetben, annak az eldöntése, hogy melyik a függő és a független változó a kutató feladata, viszont sok esetben egyértelmű.
Példa: Megfelelő módszer a vallásosság és a templomba járási szokások vizsgálatára. „Mennyire tartja magát vallásosnak?”, „Milyen gyakran jár templomba?” – ebben az esetben egyértelmű, hogy a vallásosság a független és a templomba járás a függő változó.
2. módszer: Likert skála, mint intervallum mérési szintű változó és az ANOVA teszt
A vizsgálat egy sokaság valamilyen szempont szerint kialakított csoportjait hasonlítja össze egy közös változó alapján, figyelembe véve a csoportok átlagait. Mindig a független változó lesz a faktor. Leginkább a pszichológusok alkalmazzák ezt a módszert a Likert-skála vizsgálatára. Például terápia előtti alkoholfogyasztás gyakorisága és terápia utáni alkoholfogyasztás gyakorisága.
Amennyiben a független változónk csak két csoportra van osztva, használható a T-próba is, viszont csak párok összehasonlítására alkalmazható, míg az ANOVA esetében több csoport átlaga is összehasonlítható.
Az Spss-ben az Analyze – Compare Means almenüben találjuk meg a One-Way ANOVA próbát. Ráklikkelve a megjelenő párbeszédablakban megjelöljük a függő változót (a fenti példában ez az alkoholfogyasztás) és a faktort. Az Options alpontban megjelölhetjük a Descriptives opciót, így leíró statisztikát is kapunk.
A megjelenő ANOVA táblázat utolsó oszlopában megvizsgálhatjuk a szignifikancia szintet, amennyiben az összefüggés szignifikáns, megnézhetjük, hogy a leíró táblázatunkban hogyan alakultak az átlagok.
3. módszer: A Likert skála elemzése faktorelemzéssel
Amennyiben a Likert-skálánk több kérdést tartalmaz, egy többváltozós elemzést is felhasználhatunk az adatok faktorokba való csoportosítására. Amennyiben nagyon sok függő változó van, javasolt ennek a módszernek a használata, mert így a látens összefüggések is feltárhatóak, attitűdvizsgálatok esetén kiválóan alkalmazható.
Spss-ben az Analyze-Data Reduction almenüben található meg. A megjelenő ablakban kiválasztjuk a vizsgálni kívánt változókat. Ezt követően a faktorelemzés menüpont Extraction parancsára kattintva kiválasztjuk a tömörítés módszerét (a legelterjedtebb és a legkönnyebben alkalmazható a főkomponens-elemzés).
Alapértelmezetten a megadott iterálás szám 25, viszont a pontosság növelése érdekében növelhető ez a szám szintén az Extraction menüpontnál. A Continue gombra kattintva visszakerülünk az előző párbeszédablakhoz, ahol most a Descriptives menüpontra megyünk rá, ahol kiválasztjuk az alkalmazhatóság vizsgálatára szolgáló Correlation Matrix Coefficients és Significance levels opciókat. Szintén itt kérhető le a KMO and Bartlett’s test of sphericiy is, amely szintén az alkalmazhatóság vizsgálatához szükséges. Amennyiben a tesztek azt mutatják, hogy a faktorelemzés alkalmazható, akkor neki is kezdhetünk. Viszont fontosnak tartom megjegyezni, hogy a kialakult faktorok értelmezését, értelmezhetőségének vizsgálatát nem végzi el a program, az a kutató feladata lesz.
Az output ablakban megjelenő Communalities táblázatban megvizsgáljuk a változók kommunalitását, minden változó esetében 0,25 felett kell legyen a faktorelemzés után kapott érték (a táblázat második sorában találhatóak). Amennyiben ez nem igaz minden változónkra, akkor vagy a faktorok számát kell változtatni vagy kivenni azokat a változókat, amelyek nem érik el a küszöbértéket, viszont ez információvesztéssel jár. Szintén a kutató feladata lesz eldönteni, hogy az adott téma esetében mi a jobb megoldás.
Szintén az Extraction menüben állítható a faktorok száma, ami a téma milyenségétől függően változtatható. Érdemes keresni már létező elméleti modellt, amely segítséget nyújthat a faktorok számának megítélésénél. Szem előtt kell tartani, hogy a kumulált információ érték ne legyen kevesebb 50%-nál. Ezt az Output ablakban megjelenő Total Varince Explained táblázat utolsó oszlopában nézhetjük meg. Minél nagyobb ez az érték, annál kevesebb információ veszik el a változók számának csökkentésével (pl. Az eredeti változóink száma 20 és a kialakított faktorok száma 3 és a faktorok információértéke 60%, ami azt jelenti, hogy a létrehozott faktoraink az eredeti változók információtartalmának 60%-át őrzi meg, és a változók száma lényegesen lecsökkent, tehát megéri létrehozni a faktorokat).
Ezt követően megnézzük a faktor súlymátrixot, minden változó csak egyetlen egy faktorhoz tartozhat és az az lesz, amelyen a legnagyobb súllyal van. Amennyiben vannak változók, amelyek több faktorhoz is tartoznak, akkor nem értelmezhetőek a faktoraink. Egy változó akkor tartozik csak egyetlen faktorhoz, amennyiben a második legnagyobb súlyú faktornál található érték kétszerese, kisebb mint a legnagyobb súlyú faktornál található érték.
Ha nem értelmezhetőek a faktoraink, akkor lehetőségünk van újabb matematikailag helyes megoldás megtekintésére, viszont ezekben az esetekben is a kutató feladata megállapítani a megoldás helyességét az adott témára vonatkozóan. Az új megoldásokat a faktorok forgatásával érjük el, amelyet a Factor Analysis párbeszédablak Rotation pontjánál állíthatunk be. A különböző forgatás típusok különböző megoldásokat eredményeznek. Számunkra az lesz a megfelelő megoldás, amelyben minden változónk egy faktorhoz fog tartozni.
Még több információ a faktorelemzésről: faktoranalízis.