Logisztikus regresszió
A logisztikus regresszió megbecsüli egy bizonyos esemény (a függő változó) bekövetkezésének valószínűségét. A diszkriminanciaelemzés altervatívája. Alkalmazási előfeltételei sokkal kevésbé szigorúak, mint a diszkriminanciaelemzésé. Egy függő változó és kettő vagy több független változó közötti kapcsolat leírására szolgál. Általában a függő változó egy esemény. Az elemzés során azt vizsgáljuk, hogy ez az esemény bekövetkezik-e, vagy sem. Ehhez meg kell vizsgálnunk az összes olyan tényezőt, amely összefüggésbe hozható az eseménnyel. A logisztikus regressziót leggyakrabban egy esemény előrejelzésére használják.
Példa 1: A vállalatok egymásnak nyújtott hiteleinek kockázatát szeretnénk megvizsgálni.
Példa 2: Azt, hogy valaki drogfüggő vagy nem, milyen mértékben magyarázza a nem, a családi állapot, az életkor, a jövedelem, stb.
Az eljárás valószínűségi eloszláson alapuló számítást hajt végre. A függő változót logit változóvá kell transzformálni. A maximum likelihood becslést alkalmazzák a leggyakrabban. A likelihood ratio teszttel pedig megvizsgálható a modell mutatóinak alkalmassága. A végeredmény az esély-arány, azaz az odds ratio (OR). Ez két esély aránya - angolul: odds. Az esélyt külön-külön kiszámítja az SPSS program akkor, ha egy bizonyos feltétel fennáll, illetve nem áll fenn, és a két esély arányát adja meg.
Regression - Logistic és Regression - Probit: a regressziónak azon speciális estei, amikor a függőváltozó dichotóm, azaz csak két értéket vehet fel.
A logisztikus regresszió 3 típusa
- 1. Bináris - a megfigyelt eseménynek csak két állapota van. Vagyis ha a megmagyarázni kívánt függő változónk kétértékű (dichotóm változó), a magyarázó, független változóink pedig mennyiségi vagy kategoriális változók. Az ábrázolás során a függő változó (bináris) kerül az y tengelyre.
- 2. Multinomiális - más néven: polychotomus - a megfigyelt esemény több állapotú vagyis a függő változónknak több, mint két kategóriája van. Ez a több kategóriájú függő változó pedig nominális mérési szintű.
- 3. Ordinális - a függő változónk ordinális mérési szintű. Az ordinális logisztikus regressziónak több féle változata van. A leggyakrabban alkalmazott típusa a kumulatív logit.
Előfeltételei
- A változók között nincs multikollinearitás.
- A független változók lineárisan kell utaljanak a függő változóra.
- NEM követeli meg a normális eloszlást.
- NEM feltételez linearitást a függő és a független változók között.
Mikor használjuk?
Amikor közvetett hatásokat akarunk kimutatni.
Ha a diszkriminanciaanalízis előfeltételei nem teljesülnek, akkor választhatjuk a logisztikus regressziót, amely előbbinek az alternatívájaként alkalmazható.
Amikor egy eseményt szeretnénk előrejelezni.
Fogalmak, amelyeket tudni kell:
1.valószínűség, 2.esély, 3.feltételes esély, 4.esélyhányados
1.Valószínűség (probability)
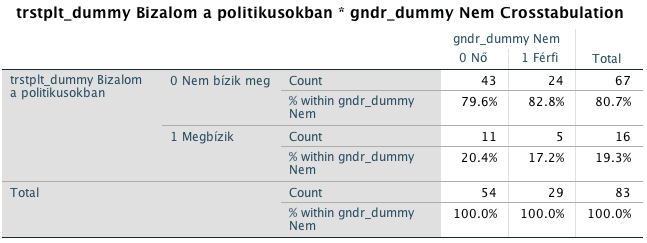
1.Feladat: Mi a valószínűsége annak, hogy valaki megbízik a politikusokban?
a) Az esetek bekövetkezésének a számát elosztod az összes eset számával.
16/83
b) Ha a százalékokból akarod kiszámolni, akkor:
A százalékot elosztod 100-al :19,3/100
2.Feladat: Mi a valószínűsége annak, hogy valaki nem bízik meg a politikusokban?
a) Az esetek bekövetkezésének a számát elosztod az összes eset számával:
67/83
b) A százalékot elosztod 100-al:
80,7/100
2. esély (odds):
1.Feladat: Mi az esélye annak, hogy valaki megbízik a politikusokban?
a) A kedvező esetek számát elosztod a kedvezőtlen esetek számával:
16/67
b) A kedvező esetek százalékát elosztod a kedvezőtlen esetek százalékával:
19,3/80,7
2. Feladat: Mi az esélye annak, hogy valaki nem bízik meg a politikusokban?
a) 67/16
b) 80,7/19,3
3. feltételes esély (conditional odds):
1.Feladat: A nők körében mi az esélye annak, hogy valaki megbízik a politikusokban?
a) Az esetek száma, amikor ez megtörtént osztva az esetek számával, amikor ez nem történt meg, mindez abban a bizonyos oszlopban, amelyre kíváncsiak vagyunk (oszlop neve: Nő).
11/43
b) azt a százalékot, amelyik a megtörtént esetekre vonatkozik, elosztod a nem megtörtént esetekkel - mindezt abban az oszlopban, amelyre a kérdés utal.(oszlop neve: Nő)
20,4/79,6
2.Feladat: A férfiak körében mi az esélye annak, hogy valaki megbízik a politikusokban?
a) Az esetek száma, amikor ez megtörtént osztva az esetek számával, amikor ez nem történt meg, mindez abban a bizonyos oszlopban, amelyre kíváncsiak vagyunk (oszlop neve: Férfi).
5/24
b) azt a százalékot, amelyik a megtörtént esetekre vonatkozik, elosztod a nem megtörtént esetekkel - mindezt abban az oszlopban, amelyre a kérdés utal.(oszlop neve: Férfi)
17,2/82,8
4. Esélyhányados (odds ratio)
Az SPSS az esélyhányadost úgy számolja ki, hogy először megnézi az első bal oldali cellára vonatkozó feltételes esélyt és elosztja az első sorban levő második cellára vonatkozó feltételes eséllyel.
Tehát az esélyhányados ebben az esetben az első cellára vonatkozó feltételes esélyt (Mi a nők körében az esély arra, hogy nem bíznak meg a politikusokban?) elosztja az ugyanabban a sorban álló, második cellára vonatkozó feltételes eséllyel (Mi az esély a férfiak körében arra, hogy nem bíznak meg a politikusokban?).
Ugyanazt az eredményt kapjuk ha az esetszámokkal vagy a százalékokkal számoljuk ezt ki:
a) esetszámokkal: (43/11) osztva (24/5)
b) százalékokkal: (79,6/20,4) osztva (82,8/17,2)=3,9/4,81=0,81
Tehát a nők 0,81-szer akkora eséllyel nem bíznak a politikusokban, mint a férfiak. Vagyis kicsit magyarosabban: a nők 0,81-szer akkora eséllyel bizalmatlanok a politikusokkal szemben, mint a férfiak.
Ha felcserélnénk a függő változó kategóriáit (0-megbízik és 1-nem bízik meg), akkor a következőképpen számolnánk ki az esélyhányadost: (11/43) osztva (5/24)=0,25/0,20=1,25
Tehát a nők 1,25-szer nagyobb eséllyel állítják azt, hogy megbíznak a politikusokban, mint a férfiak.
Ha ezt át szeretnénk alakítani százalékká, akkor a következő képletet kell használni:
(esély-1)*100=(1,25-1)*100=25
Tehát a nők körében 25%-al nagyobb az esélye annak, hogy megbíznak a politikusokban, mint a férfiak.